Figure 3: the low-rank product of Bernoulli experts' conditional posterior model.
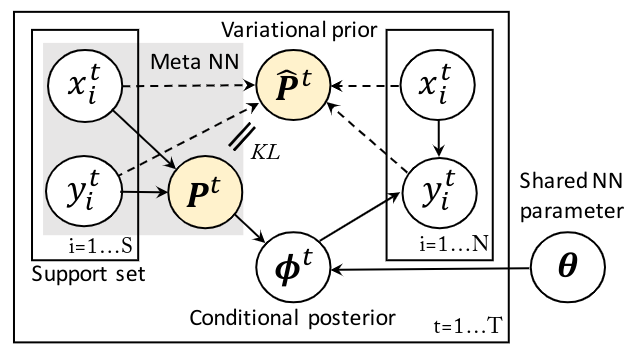
The probabilistic graphical model of NVDPs with the concept of variational prior.
Figure 4.: The 1D few-shot regression results on GP dataset. The black (dash-line) represents the true unknown task function. Black dots are a few context points (S = 5) given to the posteriors. The blue lines (and light blue area in learned variance settings) are mean values (and variance) predicted from the sampled NNs.
Figure 5.: The result of 2D image in-painting tasks on the MNIST, CelebA, and Omniglot dataset.
Figure 6. Few-shot classification results on Omniglot and MiniImageNet dataset