# IB-GAN
## Disentangled Representation Learning
* Disentangled representations: a change in a single direction of the latent vector corresponds to changes in a single factor of variation of data while invariant to others.
* GOAL: Learning an Encoder that can predict the disentangled representation. Learning a Decoder (or Generator) which can synthesize an image.
* HARD: Achieving the goal without truth generative factors or supervision is hard.
## Information Bottleneck (IB) Principle
* GOAL: Obtaining the optimal representation encoder q\_ϕ (z│x) that balances the trade-off between the maximization and minimization of both mutual information terms.
* I(⋅,⋅) denotes mutual information (MI) between input variable X and target variable Y.
* The learned representation Z acts as a minimal sufficient statistic of X for predicting Y.
## Information Bottleneck GAN
IB-GAN introduces the upper bound of MI and 𝛽 term to InfoGAN’s objective, inspired by IB principle and 𝛽-VAE for the disentangled representation learning.
𝑰^𝑳 (⋅,⋅) and 𝑰^𝑼 (⋅,⋅) denote the lower and upper-bound of MI, respectively (𝜆 ≥𝛽). IB-GAN not only maximizes the shared information between the generator 𝐺 and the representation 𝑧 but also allows control of the maximum amount of information shared by them using 𝛽 analogously to that of 𝛽-VAE and IB theory.
## Inference
### Variational Lower-Bound
* The lower bound of MI is formulated by introducing the variational reconstructor 𝒒\_𝝓 (𝒛|𝒙). Intuitively, the maximization of MI is achieved by reconstructing an input code 𝑧 from a generated sample 𝐺(𝑧)=𝑝\_𝜃 (𝑥│𝑧), similar to the approach of InfoGAN.
### Variational Upper-Bound
* Naïve variational upper-bound of generative MI introduces an approximating prior 𝒅(𝒙). However, any improper choice of 𝒅(𝒙) may severely downgrade the quality of the synthesized sample from generator 𝒑\_𝜽 (𝒙|𝒛).
* We developed another formulation of variational upper-bound of MI term based on the Markov property: if any generative process follows 𝑍→𝑅→𝑋, then 𝐼(𝑍,𝑋)≤𝐼(𝑍,𝑅). Hence, we use an additional stochastic model 𝑒\_𝜓 (𝑟│𝑧). In other words, we let 𝐺(𝑟(𝑧)).
## IB-GAN Architecture (tractable approximation)

* The IB-Gan introduces the stochastic encoder 𝑒\_𝜓 (𝑟│𝑧) before the generator to constrain the MI between the generator and the noise 𝑧.
* IB-GAN is partly analogous to that of 𝛽-VAE but does not suffer from the shortcoming of 𝛽-VAE generating blur image due to MSE loss and large 𝛽≥1.
* IB-GAN is an extension of InfoGAN, supplementing an information-constraining term that InfoGAN misses, and shows better performance in disentanglement learning.
## Experiment
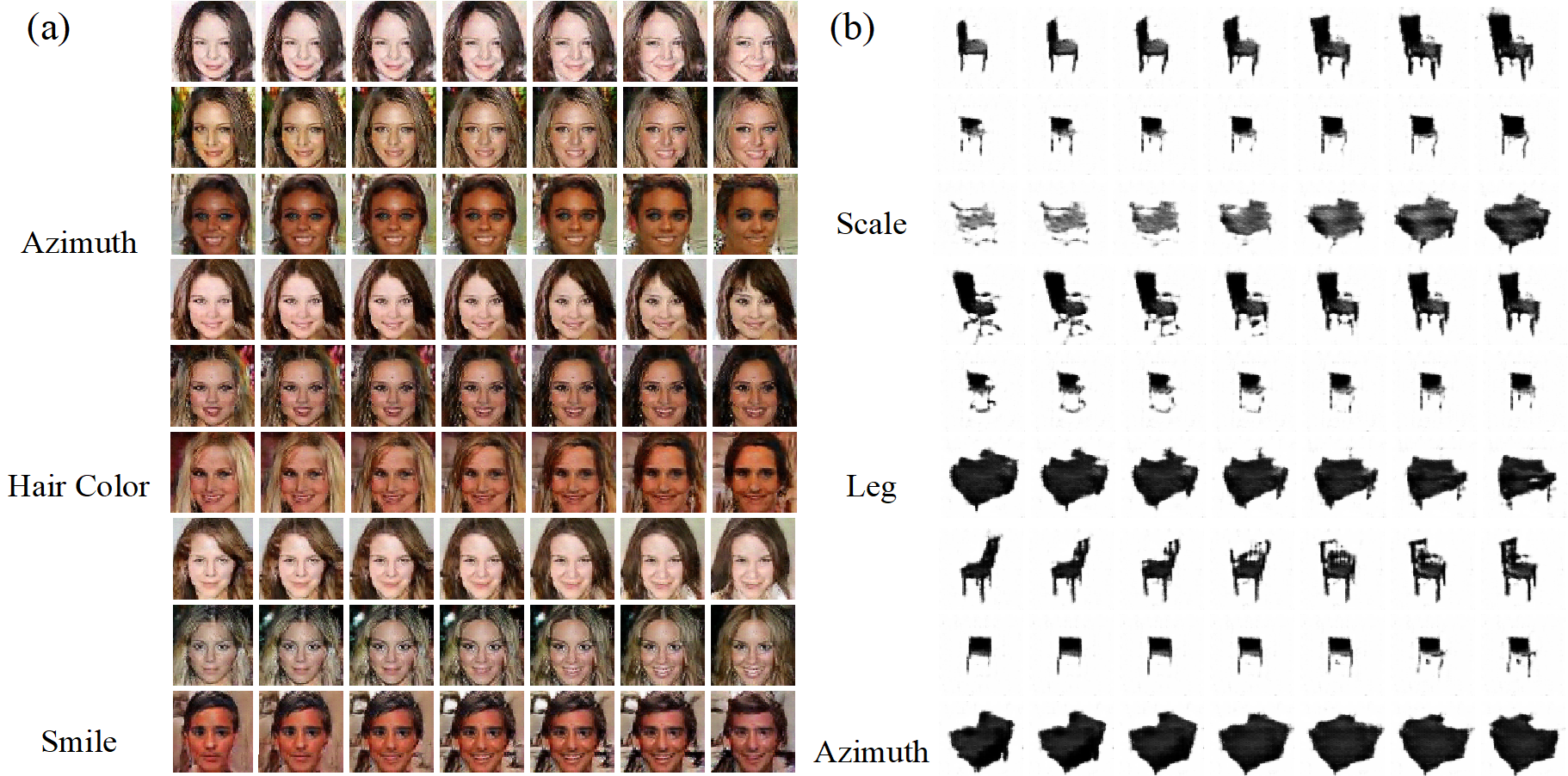
Example of generated images from IB-GAN in the latent traversals experiment [1]. (a) IB-GAN captures many attributes on the CelebA [2] and (b) 3D Chairs dataset [3].
* Comparison between methods with the disentanglement metrics in \[1,5]. Our model’s scores are obtained from 32 random seeds, with a peak score of (0.826, 0.74). The baseline scores except InfoGAN are referred to \[6].
## Conclusion
* IB-GAN is a novel unsupervised GAN-based model for learning disentangled representation. The IB-GAN's motivation for combining the GAN objective with the Information Bottleneck (IB) theory is straightforward. Still, it provides elegant limiting cases that recover both the standard GAN and the InfoGAN.
* The IB-GAN not only achieves comparable disentanglement results to existing state-of-the-art VAE-based models but also produces a better quality of samples than standard GAN and InfoGAN.
* The approach of constructing the variational upper bound of generative MI by introducing an intermediate stochastic representation is a universal methodology. It may advance the design of other generative models based on the generative MI in the future.
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://insujeon.gitbook.io/me/published-papers/ib-gan.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.